

二元反馈,仅提供关于任务成功或失败的信息,足以驱动运动学习。虽然二元反馈可以诱导运动策略的显式调整,但这种类型的反馈是否也诱导内隐学习尚不清楚。我们通过在组间设计中逐渐将一个看不见的奖励区域从视觉目标移动到最终旋转7.5°或25°来检验这个问题。参与者收到二元反馈,表明运动是否与奖励区相交。在训练结束时,两组人都将他们的伸臂角度调整了大约95%。我们通过在随后的无反馈效应阶段测量内隐学习的表现来量化内隐学习,在这个阶段,参与者被告知放弃任何已采用的运动策略,直接接触视觉目标。结果显示,在两组中,一个小的,但稳健(2-3°)的后效,突出了二元反馈引发内隐学习。值得注意的是,在两组中,对两个侧翼泛化目标的到达都与后效偏向同一方向。这种模式与内隐学习是一种使用依赖学习的假设不一致。相反,结果表明二元反馈足以重新校准感觉运动图。
精确动作的执行依赖于感官反馈。各种感觉运动适应实验被用来研究不同形式的反馈在运动学习中的作用。在一个典型的视觉运动适应实验中,参与者在看不见的手仅限于视觉光标的反馈下进行目标导向的中心向外伸展运动。为了研究学习,改变光标的位置,导致感官预测误差,通过预测光标位置与实际光标位置之间的差异来定义(Izawa and Shadmehr 2011;Kim et al. 2018;Morehead et al. 2017;Shadmehr et al. 2010;Synofzik et al. 2008;Tseng et al. 2007)。这种方向性错误可以驱动不同形式的学习。它可以产生所谓的感觉运动地图的重新校准,这样,随后的目标运动将朝着与受干扰反馈相反的方向移动,这一过程被称为感觉运动适应(Kim et al. 2021;科莱考尔2009;Krakauer et al. 2019)。它还可以引出明确的策略来减少错误;例如,参与者可能会远离目标(Bond and Taylor 2015;Taylor et al. 2014)。
反馈也可以局限于传递成功或失败的二进制信息。在完成任务时,成功可以通过手穿过一个无形的奖励区域来定义。为了激发学习,奖励区从目标区移开。这可能会以一种突然的方式完成。例如,成功突然要求玩家进入以目标为中心30°的奖励区域。或者,奖励区域可以以渐进的方式移动,例如以5°的增量最终达到30°的最大位移。在引入扰动之后,成功需要一个偏离目标的运动。虽然参与者可能会发现,当转变很大或突然引入时,学习是具有挑战性的(Brudner et al. 2016;Holland等人,2018),许多研究表明,当以渐进的方式引入转换时,二元反馈足以产生学习(Cashaback等人,2019;Izawa and Shadmehr 2011;Therrien et al. 2016, 2018;van der Kooij et al. 2021;van der Kooij and Smeets 2018)。
虽然感官预测错误和二元奖励反馈可以产生类似的行为调整,但与这两种学习形式相关的表征变化存在显著差异(Morehead and Orban de Xivry 2021;Therrien and Wong 2022)。例如,当在动作和反馈之间引入任何延迟时,来自感官预测误差的适应会大大减弱,而来自二元奖励反馈的适应则会受到几秒钟内延迟的最小影响(Brudner et al. 2016;Schween and Hegele 2017)。此外,与基于错误的反馈相比,获得性行为在基于奖励的反馈后更加持久(Bao and Lei 2022;Galea et al. 2015;Shmuelof et al. 2012;Therrien et al. 2016)。
学习过程也可以根据它们导致行为的内隐和外显变化的程度来评估。大量文献表明,感官预测错误的适应以自动和隐性的方式发生(Kim等人,2018;Mazzoni and Krakauer 2006;Morehead et al. 2017)。重新瞄准也可以产生适应性,这是明确的,在意志控制下的。到目前为止,对响应二元反馈的行为的隐式变化知之甚少。根据适应性文献的惯例,对内隐学习的有力探索是关注在反馈被消除、参与者被提醒直接接触目标时持续存在的行为变化(Maresch et al. 2021a, b)。在奖励反馈之后以这种方式进行探索时,观察到一个小的后效。例如,在奖励区域移动25°后,后效阶段开始时的平均头球角度约为5°(Holland et al. 2018)。这表明,基于奖励的学习在很大程度上是策略的意志改变的结果。与这一假设一致,通过引入次要任务来破坏显式过程会减弱从二元反馈中学习的效果(Codol等人,2018;Holland et al. 2018)。尽管如此,存在后遗症的事实,即使很小,也表明二元反馈可以诱导内隐学习(Codol et al. 2018;Holland等人,2018,2019)。
这个隐式分量的来源是什么?我们可以考虑两个不相互排斥的假设。第一个假设的核心思想是,由二元反馈引起的行为改变包括内隐的、使用依赖的学习。顾名思义,使用依赖学习指的是对频繁重复动作的运动偏好(Diedrichsen et al. 2010;Huang et al. 2011;Marinovic et al. 2017;Mawase et al. 2017;Tsay et al. 2022;Verstynen and Sabes 2011)。跟踪奖励区域将导致移动朝着与视觉目标一致的方向移动。在后效阶段,使用依赖偏差会在这个方向上产生残余内隐偏差。有趣的是,使用二元反馈进行训练后的3-4°后效应与在排除动作选择错误的使用依赖学习研究中观察到的效果相似(Tsay et al. 2022)。
第二个假设是,二值反馈诱导了感觉运动图的内隐重新校准。从机制上讲,隐性重新校准可能发生,因为二元反馈改变了行动计划及其相关动作之间的偶然性。表明任务成功的反馈会加强达到视觉目标的目标和与该目标相关的动作之间的联系,即使这些动作指向的是相对于视觉目标移位的奖励区。指示任务失败的反馈会削弱这种联系。与基于错误的学习相比,奖励反馈的重新校准似乎更有限,因为对于类似的扰动大小,二元反馈的后效要比光标反馈的后效小得多(Bond and Taylor 2015;Codol et al. 2018;Holland et al. 2018;Leow et al. 2018;Taylor and Ivry 2014)。
在这里,我们报告了一个旨在评估这些使用依赖学习和内隐重新校准假设的实验结果。仅提供二元反馈,我们研究了参与者如何学会对奖励区域的小(7.5°)或大扰动(25°)做出反应。对于两组,扰动都是以渐进的方式引入的。假设小扰动条件下的参与者几乎没有意识到扰动,这个条件为内隐过程在基于奖励的学习中的作用提供了强有力的测试。相反,我们假设大条件下的参与者最终会采用一种策略。
为了评估这两种情况下的内隐学习,我们在后效阶段测量了伸手量,在这个阶段,所有的反馈都被消除,参与者被指示直接伸手到目标。隐式再校准和使用依赖假设都预测了小条件和大条件下的后效。为了比较这两种假设,我们在后效阶段纳入了两个探针目标,与训练目标位置偏移了15°(图1c)。包括探测目标允许我们问内隐学习,如果观察,如何推广。通过隐式再校准假设,我们期望到达探测目标的距离与到达训练目标的距离在相同的程度和方向上有偏差。根据使用依赖假设,我们可以观察到,到达探测目标的手会被训练过的动作所吸引。对于小摄动条件,由于训练的运动落在两个探针位置之间,因此对两个探针目标的偏置方向应相反。对于大扰动条件的预测不太清楚,并且将取决于学习的大小。如果参与者完全跟踪奖励区的25°移动,则对两个探测目标的偏差将在相同的方向上。然而,如果训练后的动作低于奖励区域,那么当训练后的动作小于15°时,偏差就会变得不那么对称,甚至出现相反的迹象。
图1
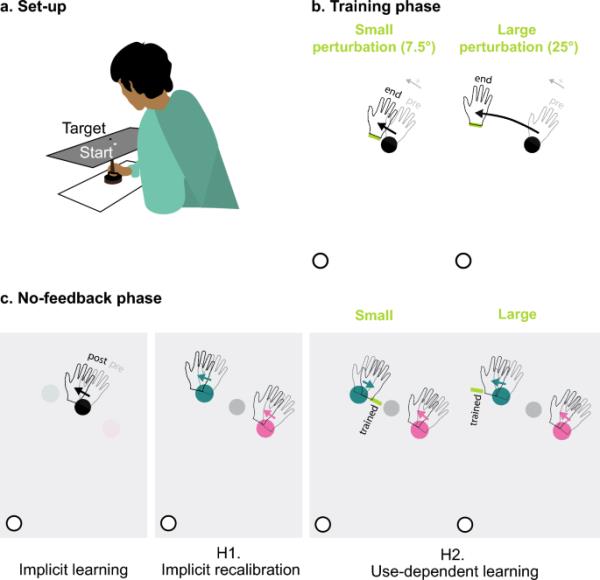
基于内隐奖励的运动学习的主要假设的概要。实验装置中参与者的示意图。b培训阶段。参与者从一个白色的起始圈到一个黑色的训练目标做一个向中心伸出的动作。当运动通过奖励区(绿色拱形)时,会发出悦耳的“叮”声;否则,就会响起令人不快的“嗡嗡声”。c无反馈阶段。参与者被指示直接接触一个视觉目标。目标出现在训练位置或两个探针位置之一(±5°)。参与者被要求放弃在训练阶段采用的任何策略。左图显示内隐学习是通过后效来衡量的,定义为从训练前(半透明手)到训练后(实心手)到达训练目标的手角度的变化。中间面板显示探测目标达到隐式再校准假设的预测。对于两个探测目标,到达将偏向同一方向,与扰动的大小无关。右图显示了使用依赖学习假说的探测目标达到预测。对于小扰动条件,由于训练期间的河段位于两个探针位置之间,因此偏差将在相反的方向上。在大扰动条件下,距离奖励区最近的探测目标的偏置方向取决于学习的程度。在这里描述的例子中,参与者表现出充分的学习(超过两个探测目标,> 15°),因此,使用依赖预测的偏差方向对于两个探测目标是相同的。对于表现出学习减少的参与者(在两个探测目标之间,< 15°),使用依赖学习的预测如小扰动所示
研究人员从加州大学伯克利分校心理学系的研究参与者中招募了68名惯用右手的年轻人。28人(女性22人,男性6人;报告年龄:平均20.5岁,SD 2.3岁)被分配到“小”扰动组和40例(27例女性,13例男性;报告年龄:平均21.5岁,标准差5.7岁)被分配到“大”扰动组。参与者可以获得课程学分或经济补偿,并向所有参与者支付5美元的完成奖金。根据参与者的自我报告,他们的视力和听力正常或矫正到正常。该方案得到了加州大学伯克利分校机构审查委员会的批准。
在最初的68名参与者中,有20人被排除在所有分析之外。其中16人(每组8人)根据他们对实验后问卷的回答(见“实验设计”)被排除在外,该问卷表明他们没有遵循说明。这个大群体中的另外四名参与者因特殊原因被排除在外:一个人在任务中睡着了,一个人在做了类似的实验后报告说,一个人没有正确使用仪器,还有一个人经历了设备故障。因此,下面报告的分析是基于从20名参与者(16名女性;10学分;报告年龄:平均20.9岁,SD 2.4岁)在小扰动组和28名参与者(16名女性;16学分;大扰动组报告年龄:平均21.8岁,SD 6.0岁)。
参与者坐在一间昏暗的小房间里的一张桌子前。水平方向的电脑屏幕(24″,ASUS, Taipei, Taiwan)构成了桌子的上表面,17″数字化平板电脑(Wacom Co., Kazo, Japan)位于屏幕下方27厘米处(图1a)。刺激在计算机上呈现(刷新率=60 Hz),参与者沿着数字化平板的运动被记录在数字化笔(采样率=200 Hz)中,该笔嵌入定制的桨中,确保笔保持垂直位置。那只手被屏幕遮住了。使用一台计算机(Dell OptiPlex 7040, Round Rock, Texas)和Windows 7操作系统(Microsoft Co., Redmond, Washington)在Matlab (the MathWorks, Natick, Massachusetts)中运行定制的实验软件,使用Psychtoolbox扩展(Brainard 1997;Kleiner et al. 2007)。
每次试验开始时,屏幕中心附近出现一个白色的“起始”圆(半径=0.42 cm)。参赛者被要求移动桨把数字笔放在起始圈内。为了引导参与者到达起始位置,会出现一个白色的圆环,圆环的半径表示从笔到起始位置的距离。向起始位置移动减小了环的尺寸。当笔距起始圆圈0.84厘米时,圆圈被一个白色圆圈(半径0.17厘米)取代,该圆圈表示笔的位置,允许参与者将笔移动到起始圆圈内。
当桨在起始圆圈中停留300毫秒时,距离起始圆圈7厘米处出现一个视觉目标(半径为0.28 cm的圆圈),其方向为45°、60°或75°(图1b、c)。参与者被指示快速移动,试图切开目标。当运动幅度超过7 cm时出现听觉反馈。在有表现反馈的试验中(见下文),一个令人愉快的“bing”表示动作成功(例如,当反馈是真实的时,通过了目标),一个令人厌恶的“嗡嗡声”表示动作不成功。在没有反馈的试验中(在基线和后效阶段),会播放“敲击声”。这表明已经超过了要求的到达幅度,但它并没有提供关于运动是否在奖励区域内的反馈。
为了使参与者以相似且相对较快的速度移动,如果移动时间超过600毫秒,则在表现反馈后800毫秒播放“太慢”的听觉信息。3%的试验都是这样。请注意,这些试验被包括在分析中,因为参与者在这些试验中得到了奖励反馈,因此预计他们会对学习有所贡献。
反馈环在反馈后直接出现。请注意,在返回运动期间使用环,参与者收到的反馈仅表明手的径向位置。只有当手非常接近起始位置时才提供角度位置:然后,环变成光标。使用这种方法,使任何适应旋转反馈的影响(见下文)在返回运动期间对参与者来说是最小可见的。
实验者告诉参与者,实验的目的是研究人们在没有视觉反馈的情况下控制手臂运动的能力。参与者被告知,他们将控制一个看不见的光标,他们被要求做出伸手的动作,使看不见的光标与视觉目标相交(图1a)。实验人员分别描述了“叮”和“嗡嗡”是如何指示触碰目标或未触碰目标的。然后,实验者完成了10个示范实验来演示手是如何控制光标移动的。目标始终呈现在60°位置,在这些试验中,听觉反馈伴随着垂直光标反馈。
在10个示范试验后,被试被告知,光标在到达过程中不再可见,但在大多数试验中会出现听觉反馈来指示任务结果。然而,在一些试验中,参与者会听到“敲门声”,这种声音与任务结果无关。为了激励参与者参加所有的试验,参与者被告知,计算机会记录所有成功的测试,并且在所有参与者中得分最高的前三分之一的人将获得5美元的奖金(实际上是支付给所有参与者的)。
主实验分为基线、训练、效果三个阶段,每个阶段开始由实验者进行指导。基线阶段由150个试验组成,反馈仅限于无信息的“敲击声”。在50个基线试验中,目标出现在三个可能的位置中的每一个,顺序随机确定。这些试验使参与者熟悉了设备,学会了以适当的速度移动,并为三个目标位置中的每个位置提供了自然偏差的测量(Kuling et al. 2019;van der Kooij et al. 2013)。
训练阶段由700次试验组成,目标总是出现在中间位置(60°),并提供听觉反馈来指示目标命中或未命中。在前100次试验中,奖励区以参与者到达训练目标时的个体偏差为中心,并向两个方向延伸2°;例如,如果个体到达中心目标的平均距离沿顺时针方向旋转3°(57°),则初始奖励区域从55°扩展到59°。参与者不知道的是,在接下来的500次试验中,奖励区域逐渐转移。这是通过在小扰动组每100次试验中将奖励区旋转1.5°和在大扰动组每50次试验中将奖励区旋转2.5°来实现的。旋转是顺时针或逆时针,在参与者之间平衡。在训练阶段的最后100次试验中,小扰动组和大扰动组的奖励区保持固定,分别从起始位置偏移7.5°或25°。在700个试验训练阶段的中途提供了2分钟的休息时间。
请注意,我们预计Small组中的参与者可能不会意识到扰动,因为位移是逐渐引入的,总位移落在正常到达变异性的1-2个标准差范围内(Gaffin-Cahn et al. 2019)。相比之下,我们预计大组的参与者可能会在训练阶段的某个时刻意识到扰动,因为视觉目标和手部运动之间的差异可能超出了个体的正常到达变异性。
在训练阶段之后,参与者完成了150次试验的后遗症阶段。在这个阶段开始之前,参与者被告知,在培训阶段的过程中,反馈可能会被改变。为了平等地告知和指导具有不同程度扰动意识的参与者,参与者被告知有两组参与者,一组对齐组和一组不对齐组。对于对齐的一组,看不见的光标总是与手的位置精确地移动;对于不对齐组,看不见的光标从手的位置略微移位。为了确保参与者理解差异,他们被要求用自己的话解释两组之间的差异。如果解释没有捕捉到差异,实验者就重复解释。然后,实验人员声明,在实验的最后阶段,光标将与每个人的手对齐,无论最初的小组分配如何,因此,他们应该直接到达目标,使光标击中目标。与基线阶段一样,在此阶段中,仅使用无信息的反馈执行到达,该阶段由对三个目标中的每个目标的50个到达组成。参与者再次被告知,在这一阶段将记录准确性,以确定最终的表现奖金。
在实验结束时,参与者完成了一份由五个问题组成的问卷(在线资源1)。问题1询问他们是否相信反馈是真实的还是令人不安的,问题2询问他们对问题1的回答的信心,使用7分量表(1=不自信,7=非常自信)。对于问题3和4,参与者被要求分别报告(强制选择)他们在训练阶段和效果阶段的目标。请注意,问题4用于确定参与者是否遵循了指示。那些回答说他们在后遗症阶段瞄准了目标的左边或右边的人被排除在所有的分析之外(n=16)。在第5个问题中,参与者被告知他们属于不一致的反馈组,并被要求指出(强制选择)反馈是否受到干扰:向左还是向右。由于这个问题的答案在小扰动组中低于机会水平,对于大扰动组,两个选择的插图略有变化,以更好地匹配参与者的手部运动。
实验总时间约为1小时。
根据Holland等人(2018)报告的数据,在我们的任务中,需要21个样本量来检测内隐学习,功率为0.80。我们分别为大扰动组和小扰动组招募了40名和28名参与者,以使我们安全地超过这个数字。然而,如上所述,由于各种排除标准,大组和小组的最终样本量分别为28和20。
到达角由起始位置到数字化笔越过起始位置周围7厘米半径处的直线确定。基线试验期间的平均伸角分别用于表征三个目标位置的个体偏差(50个伸角/目标)。所有的分析都是基于训练和后效阶段的伸入角度,这些角度表示相对于参与者对相应目标的基线偏差。正值对应于在旋转奖励区域方向上移动的到达角度。
我们将最终的学习计算为训练阶段最后100次试验中的平均伸角。为了检验内隐学习的有效性,我们计算了后效阶段到训练目标的平均到达角度。为了推广,我们计算了两个探测目标在后效阶段的平均到达角。
统计数据
初步分析表明,最终的学习成绩和后效成绩并非正态分布(见图2)。因此,我们采用非参数检验对结果进行统计评价。为了检验最终学习和后效应是否大于零,我们对每组(小组和大组)的这些变量进行了单侧Wilcoxon符号秩检验。为了检验内隐学习在两种扰动大小下是否不同,我们对两组的后效分数进行了双尾Wilcoxon秩和检验。由于每组的内隐学习值在两次统计检验中使用,我们使用0.025的显著性标准对多重比较进行了校正。
图2
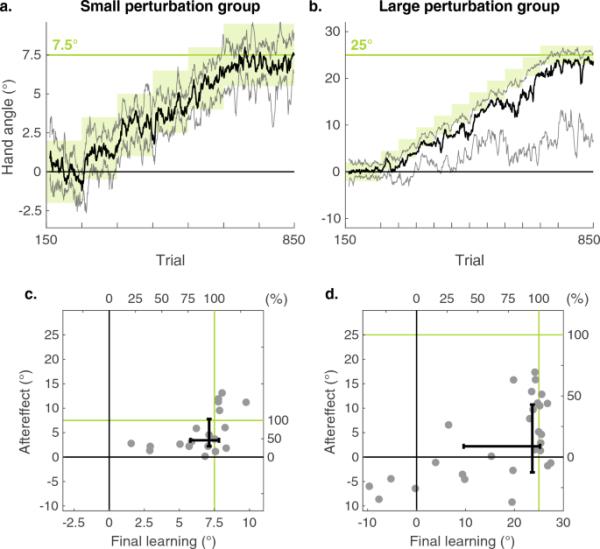
二元奖励反馈对到达的影响。a, b训练阶段。逐渐改变奖励手的角度(绿色区域)导致学习,如到达角度的变化所示。我们用小扰动组(a)和大扰动组(b)的四分位数范围(不透明线)绘制了所有参与者的中位数(粗实线)。请注意,垂直轴按扰动大小缩放。为了显示的目的,曲线用一个运行平均值平滑,窗口大小为10次试验。c, d作为两组最终学习的函数的后效。每个灰点对应一个参与者,误差条表示每组的四分位数范围。绿线表示扰动大小
对于泛化数据,我们将百分比泛化定义为两个探测目标偏差的平均值,除以训练目标的后效应。我们使用单侧Wilcoxon带符号秩检验来检验百分比概化值是否显著大于零。为了评价泛化的形式,我们将泛化不对称性定义为对奖励区相反方向的探测目标的到达偏差与对奖励区方向的探测目标的到达偏差之差。使用依赖学习假设预测,对于小扰动条件,该值将是正的。隐式重新校准假设预测该值将为零(如果两个目标的泛化完全相同,但参见(Nikooyan和Ahmed 2015))。为了评估这两个假设,我们使用了Wilcoxon有符号秩检验来检验泛化不对称值是否显著大于零。
对问卷数据不进行统计。
摘要
介绍
方法
结果
讨论
结论
数据和代码可用性
参考文献
致谢
作者信息
道德声明
补充信息
搜索
导航
#####
为了评估人们如何在奖励区逐渐变化的情况下改变他们的动作,我们分析了小(最大偏移7.5°)和大(最大偏移25°)扰动组在学习结束时的伸角。两组都学会了补偿反馈扰动(图2a, b)。小扰动组的参与者最终学习的中位数为7.1°(IQR[5.8°,7.8°],p < 0.001, z=3.9, Ws=210, r=0.20)(图2c,水平轴)。大扰动组的参与者最终学习的中位数为23.7°(IQR[9.6°,25.2°],p < 0.001, z=4.2, Ws=390, r=0.16(图2d,水平轴)。对于两组,这对应于扰动大小的95%的平均感知变化(小:IQR=77%-104%;大号:IQR=38%-101%)。
从图2c、d(横轴)可以看出,与小扰动组相比,大扰动组的学习变化更大。对于后者,所有参与者都朝着干扰的方向改变了他们的到达方向,86%的人在最后100次试验中最终的平均头球角度在最终奖励区域内。相比之下,大扰动组中只有70%的参与者到达了最终的奖励区(在线资源2)。在最后100次试验中,这组中有4名参与者的平均手角与奖励区方向相反。
本研究的中心目的是研究关于成功或失败的二元反馈是否诱导内隐运动学习。为此,在后效阶段,当反馈被移除,参与者被指示直接到达目标时,我们专注于到达方向。
两组均表现出显著的后效(图2c, d纵轴)。小扰动组参与者的中位后效为3.4°(IQR[2.2°,7.8°]);p < 0.001, z=3.90, Ws=210, r=0.20)。大扰动组参与者的中位后效为2.2°(IQR[- 3.1°,10.7°],p=0.02, z=2.02, Ws=292, r=0.07)。重要的是,我们发现小扰动组和大扰动组的后效大小没有差异(p=0.24, z=- 1.2, U=434)。
从图中可以看出,Large组中4名最终学习成绩为负的参与者也表现出了负的后遗症。当这些参与者被排除在外时,该组的中位后效增加到4.90°。与最初的分析一样,在这个二次分析中,小组和大组的后效程度没有差异(p=0.89, z=- 0.13, U=456)。
总之,后效数据表明,在对二元反馈的响应中,学习中存在隐性成分。小扰动组和大扰动组的后效大小相似,且相当小。
我们在后继效应阶段引入了对两个探测目标的到达,探讨了学习如何推广到与训练目标相邻的工作空间区域。两组都表现出普遍性,即到达探针位置的距离从基线阶段明显偏移。在移动方向上,平均值均为正,即探测目标到达方向的变化与训练目标到达方向的变化方向一致(图3a)。小扰动组的参与者在学习方向上对探测目标的中位到达偏差为3.5°,对另一个探测目标的中位到达偏差为3.6°。大扰动组的相应偏差为1.6°和0.7°。如果排除四个负的最终学习器,后者的值增加到2.3°和4.3°。
图3
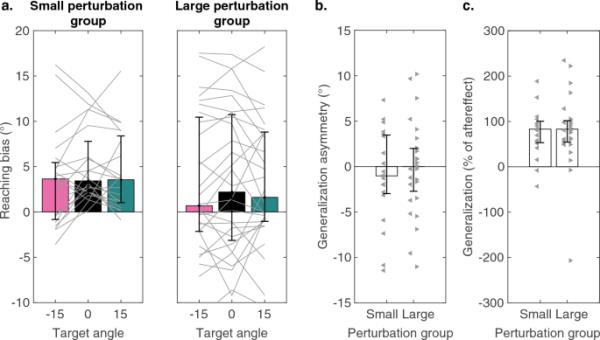
学习的后效和泛化。柱状图和误差图表示中位数和四分位数范围。a训练目标(黑色)和两个探测目标的到达偏差(见图1c)。细线表示来自个体参与者的数据。b到达探测目标偏差的不对称性。点表示个体参与者。对于大扰动组,左指向的三角形表示最终学习< 15°的参与者。直角三角形表示最终学习> 15°的参与者。c泛化量化为后遗症的百分比
概化数据与使用依赖学习假说不一致。使用依赖学习假说预测了小扰动组中两个探针在相反方向上的偏差,因为训练的运动在两个探针目标之间。这将预测正概化不对称分数。在大扰动组中,预测不太清楚,因为它们依赖于相对于探测目标的训练运动的位置。对于最终训练运动落在探测目标之间(即< 15°)的参与者,使用依赖假设将预测正概化不对称得分,类似于Small组的预测。然而,对于完全遵循奖励区域的参与者来说,训练后的动作超出了两个探测目标。因此,使用依赖假设将预测两个探测器在同一方向上的偏差,尽管大小不同(见图1c)。对于两组,分析显示不对称评分均不显著大于零(图3b;小:中位数=?1.0°,差(?3.0°,3.5°),p=0.55, z=?0.06,Ws=89;大:中值=0.0°,差(?2.7°,2.0°),差(53.3%、100.5%),p=0.96, z=?0.05,Ws=201)。此外,我们观察到最终学习与泛化不对称得分之间没有关系(图3b)。
相比之下,概化数据与隐式再校准假设一致。当到达两个探测目标时,探测偏差的方向与在训练目标上观察到的方向相同,即在扰动的方向上(图3a, b)。我们将泛化幅度计算为两个探测目标偏差的平均值,作为后效应的百分比(图3c)。这些数值在小组(p < 0.001, z=3.7, Ws=205, r=0.19)和大组(p < 0.001, z=4.0, Ws=379, r=0.14)中显著大于零。在两组中,泛化量为训练目标偏差的83%(小:IQR [53.3%, 100.5%];大:IQR[54.3%, 100.6%])。综上所述,虽然对大群体的泛化结果的解释是有问题的,但小群体的结果为隐含的再校准假设提供了强有力的支持。
正如预期的那样,小扰动组的参与者通常没有意识到奖励区在实验过程中发生了变化。当被要求判断他们是在有垂直反馈还是移动反馈的小组时,60%的人报告说反馈没有受到干扰,平均置信度为3.3,满分为7分(在线资源3)。当被迫在训练阶段选择向左、向右或直接瞄准目标时,50%的人报告说他们直接瞄准目标,50%的人报告说他们瞄准了目标。然而,在后者中,一半的人报告瞄准了移动的奖励区域的方向,另一半报告瞄准了相反的方向。这些调查数据,结合小扰动组的所有参与者都表现出向扰动方向移动的事实,提供了令人信服的证据,证明几乎没有意识到实验操作或使用补偿策略。
从大摄动组的调查数据中出现了一个非常不同的画面。大多数人(82%)表示,反馈令人不安,平均置信度为4.8分(满分7分)。当被问及他们在训练阶段是瞄准目标的左侧、右侧还是直接瞄准目标时,75%的参与者报告说他们在奖励区移动的方向瞄准了偏离目标,而21%的参与者报告说他们直接瞄准了目标。综上所述,调查数据表明,大扰动组的参与者意识到了实验操作,并采取了重新瞄准策略来补偿奖励区的变化。问卷报告与后遗症之间没有明确的关系(在线资源3)。
在本研究中,我们考察了二元反馈是否可以诱导内隐学习以响应隐藏奖励区的变化。基于之前的工作(Codol et al. 2018;Holland et al. 2018, 2019),我们预计学习将包含隐式成分。参与者完成了一个向中心伸出的任务,只提供了二元反馈,以表明运动是否在奖励区结束,该奖励区逐渐转移到距离视觉目标7.5°或25°的中心,并期望在前者中对扰动的意识将是最小的,而后者将包含一些明确的成分。在训练过程中,两组参与者都学会了补偿旋转的反馈。当训练后反馈被移除,参与者被指示移动到目标时,他们的到达偏向于学习方向,两组的后效均为2-3°。为了检验泛化,无反馈阶段还包括到达训练目标侧面的探测目标。在这些探测目标试验中,参与者表现出与训练目标相关的移动方向相同的可及角度的移动。这些结果表明,二元反馈可以诱导内隐的基于奖励的运动学习,这种学习反映了内隐的感觉运动映射的重新校准。
我们的研究采用了多种方法来防止外显过程污染我们对内隐学习的评估。首先,在没有反馈的阶段,我们关注的是后果,在这个阶段,我们提供了明确的指示,要求停止使用任何可能在训练期间使用的策略。其次,我们以渐进的方式引入了扰动,最重要的是,包括了一个小的扰动组,其中每一步的位移在基线到达变化率的1.5个标准差范围内(在线资源4)(Gaffin-Cahn et al. 2019)。因此,对于这组人来说,训练阶段的行为改变很可能是隐性的。第三,我们使用问卷直接评估扰动意识。对调查的回应证实,在扰动阶段,小扰动组的意识和策略使用最少,但大扰动组的意识和策略使用很高。
我们观察到,在小扰动组和大扰动组中,有一个小的,但一致的约2-3°的后效,这是对二元反馈的内隐学习的证据。大组的后效幅度小于先前报道的其他使用类似大小扰动的研究;例如,在Holland等人(2018年,2019年)中,当包括所有参与者(学习者和非学习者)时,响应25°扰动的后遗症约为5°。然而,在最初的无反馈后遗症阶段,Holland等人指示他们的参与者像在训练期间那样继续伸手。随后,参与者被要求停止使用一种策略。该协议可能会增加额外的策略试验和在任务之间切换的挑战,从而污染最终的后效度量。
小扰动组的包含不仅提供了在训练阶段应该最小化意识的条件,而且还允许我们直接比较扰动大小如何影响二进制反馈的内隐学习的大小。有趣的是,后效应的大小不随扰动大小成比例。确实,就平均值而言,小条件下的尺寸(3.4°)比大条件下的尺寸(2.2°)更大,尽管这种差异并不显著。在二次分析中也观察到这一无效结果,我们排除了在大条件下表现出负最终学习分数的四名参与者。
虽然未来的测试需要对更大范围的扰动大小进行采样,但目前的结果表明,至少对于大于7.5°的扰动,二元反馈的隐式学习的幅度相对较小且饱和。对于响应于15°至90°扰动的感官预测误差的内隐学习,也观察到类似的饱和(Bond and Taylor 2015;Morehead et al. 2017)。然而,内隐学习响应感官预测误差的上限在15°到25°之间(Bond and Taylor 2015;Morehead et al. 2017)。
在大扰动组的表现中观察到的大变异性确实限制了可以推断的关于内隐奖励学习如何随着扰动的大小而扩大。这一组中有相当多的参与者没有追踪到奖励区,总的来说,这些人的负面影响分数接近他们的最终学习分数。在大组中,一些成功追踪到奖励区域的参与者也观察到了负面的后遗症。正如调查数据所表明的那样(参见在线参考资料3),这些参与者通常意识到这种干扰,并调用某种形式的策略来帮助执行。假设基于内隐奖励的学习有一个很小的上限,成功地完全跟踪扰动将需要发现和维护一个目标策略。考虑到反馈的二元性和手部视觉反馈的缺失,这可能是相当可变的。在后续阶段“关闭”此策略可能会增加额外的可变性。
在下一节中,我们将考虑响应二进制反馈的内隐学习的机制。类似于基于错误的学习研究(Bond and Taylor 2015;Morehead et al. 2017)和使用依赖学习(Tsay et al. 2022),响应二元反馈的内隐学习似乎已经饱和。然而,这三种内隐学习形式之间存在显著差异。虽然内隐使用依赖偏差的大小与本研究中观察到的后效大小相似,但泛化模式没有显示出对训练地点的吸引力。因此,目前的结果不能支持从二元反馈中进行内隐学习是使用依赖学习的一种表现形式的观点。另一方面,虽然二元反馈和游标反馈的泛化模式相似,但二元反馈效应的大小远小于对游标反馈的响应(Bond and Taylor 2015;Morehead et al. 2017)。这种大小差异使得二元反馈不太可能在诱导感觉运动图的内隐重新校准的类似机制上起作用。
那么,二元反馈是如何导致内隐学习的呢?我们概述了三个隐含的重新校准假设。首先,响应二值反馈的内隐学习可能是运动重新校准的结果,重新调整视觉目标位置与其相关运动之间的映射。行动和奖励结果之间的偶然性将导致该行动与新的行动计划相关联(abraham et al. 2022)。这个假设预测没有感觉重新校准:训练不会影响视觉目标的感知位置和手的感知位置的报告,因此它们在训练前后是相似的。第二,内隐学习可能是目标视觉再校准的结果,即对视觉目标感知位置的偏差。这一假设预测了视觉感官的重新映射:例如,如果要求用未训练过的手报告感知到的目标位置,我们会观察到对奖励区的偏向(Simani et al. 2007)。第三,内隐学习可能是本体感觉再校准的结果,即对手部位置的感知偏差。这一假说预测了本体感觉的重新映射。例如,对感知到的手的位置的静态报告将偏向于与扰动相反的方向(Tsay和Ivry 2022)。
未来的研究将采用精细的心理物理测试来评估这些不同假设的优点,询问响应二元反馈的内隐学习是否源于感觉和/或运动映射的内隐重新校准,以及这在学习过程中是如何演变的。
我们的数据增加了越来越多的证据,表明运动学习包括多个过程,其中显式和内隐过程驱动行为变化(Kim et al. 2021;Morehead and Orban de Xivry 2021;Therrien and Wong 2022)。结果提供了令人信服的证据内隐学习响应二进制反馈,并排除了这种影响是一种形式的使用依赖的学习。不太清楚的是,这种内隐学习是否需要同样的机制,尽管是以弱化的形式,发生在从感官预测错误中学习的过程中,或者反映了不同的、基于奖励的机制的运作。
下载原文档:https://link.springer.com/content/pdf/10.1007/s00221-023-06683-w.pdf

